Database by LinuxAcedemy
Database by LinuxAcedemy 1
Links 2
Database design architecting concepts 2
Database design depends on 3 categories 2
Database Concepts 2
Choosing the Database 3
When to use RDB 3
Provider of RDB which provides ACID guarantee 4
Edge case 4
Architecting Database 4
Must haves 4
RDS 5
When to use 5
OLTP 5
OLAP 6
Download and Installation 6
Database 6
Type of database 7
MongoDB 8
TODO 8
Create a database 8
Update database 8
Delete a record 8
Bulk import data 9
Couchbase 9
PostgreSQL 12
Create/Read database 12
Update Table 12
Delete table 12
Drop table 12
Postgres vs MySql 13
Links
https://lucid.app/lucidchart/00cb26cf-d76f-440c-ba1c-32b3b8a1665a/view?page=~ri_7aVGqpaI#
https://www.youtube.com/watch?v=cODCpXtPHbQ&ab_channel=codeKarle
Database design architecting concepts
Database design depends on 3 categories
- How organized your data is (structured vs non-structured)
- Query pattern you have
- Amount of scale that you need to handle
Database Concepts
- Caching - use Redis
- Storage - Blob Type - Use S3 + CDN
- Text searching capabilities - Text search engine - Elastic Search + Solar = Apache Lucene
- Fuzzy search when someone types wrong spelling accidentally; database has to return the desired result
- Elastic Search and Solar are Search Engines and not databases
- Search Engines: potentially data could be lost. It provides availability and redundancy
- Database: it gives you a guarantee that data wouldn’t be lost
- Takeaways:
- Never keep search engines as your primary source of data
- primary source data store should be somewhere else; you could load the data using Search Engines to provide searching capabilities
- Store metric data/ Time series - Open TSDB
- Application metrics tracking system: apps that are pushing metrics related to their throughput, CPU utilization, and latencies.
- Now you want to build a system to support the above capabilities - use Time-series Database
- The time-series database is an extension of RDB with certain functionalities
- Regular database: you can update a lot of records, giving you the ability to query random records
- Metric monitoring system: you will never do random updates
- You’ll do a sequential update in an append-only mode where first entry T1 and second entry T2 will be greater than T1
- Read query that you do is bulk with the time range; ex: query for last hour, day, week data.
- Data warehouse for analytics - Use Hadoop
- A large database in that you dump all the data; provide various querying capabilities on top of the data to serve a lot of reports.
- Not suited for a transactional system; it’s used for offline reporting
- Analytics for all the business transactions, total orders, geographic location
Choosing the Database

If you have structured data use RDB
- Where you can store data in terms of tables = rows + columns
- ex: web app where you store user ID, email, DOB, City, PhoneNo
When to use RDB
- When you need ACID = atomicity and transactional guarantee
- ex: building a payment system in bank where one person is debiting about into another person’s account
- Query has to work fully and about either has to be debited to not called transactional query
Provider of RDB which provides ACID guarantee
- My Sql
- Oracle
- SQL Server
- Postgres
Edge case
- When you have relational data but need ACID guarantee // you can choose either relational or non-relational database
- Because normally you could easily map a structured data into no-sql model
Architecting Database
Must haves
- Multi Az for disaster capabilities
- How it works?
- Primary database in one AZ and Secondary database(exact copy of your primary database) in another AZ
- If your primary DB shuts down, server then use standby database endpoint by filing over to standby database
- It’s not used when your primary database is still running
- How technically it works?
- You get a endpoint of both of your database
- EC2 server hooked up with your primary database
- AWS automatically updated the DNS endpoint to point to another IP address of your standby DB when primary DB shuts down
- Useful for - Failover capabilities
- This is just for disaster recovery and not for improving performance
- Can’t connect to standby database when the primary database is active.
- Can’t run your queries on your second database with multi AZ
- Can’t send your web server traffic to secondary database
- Your second database simply there for failure
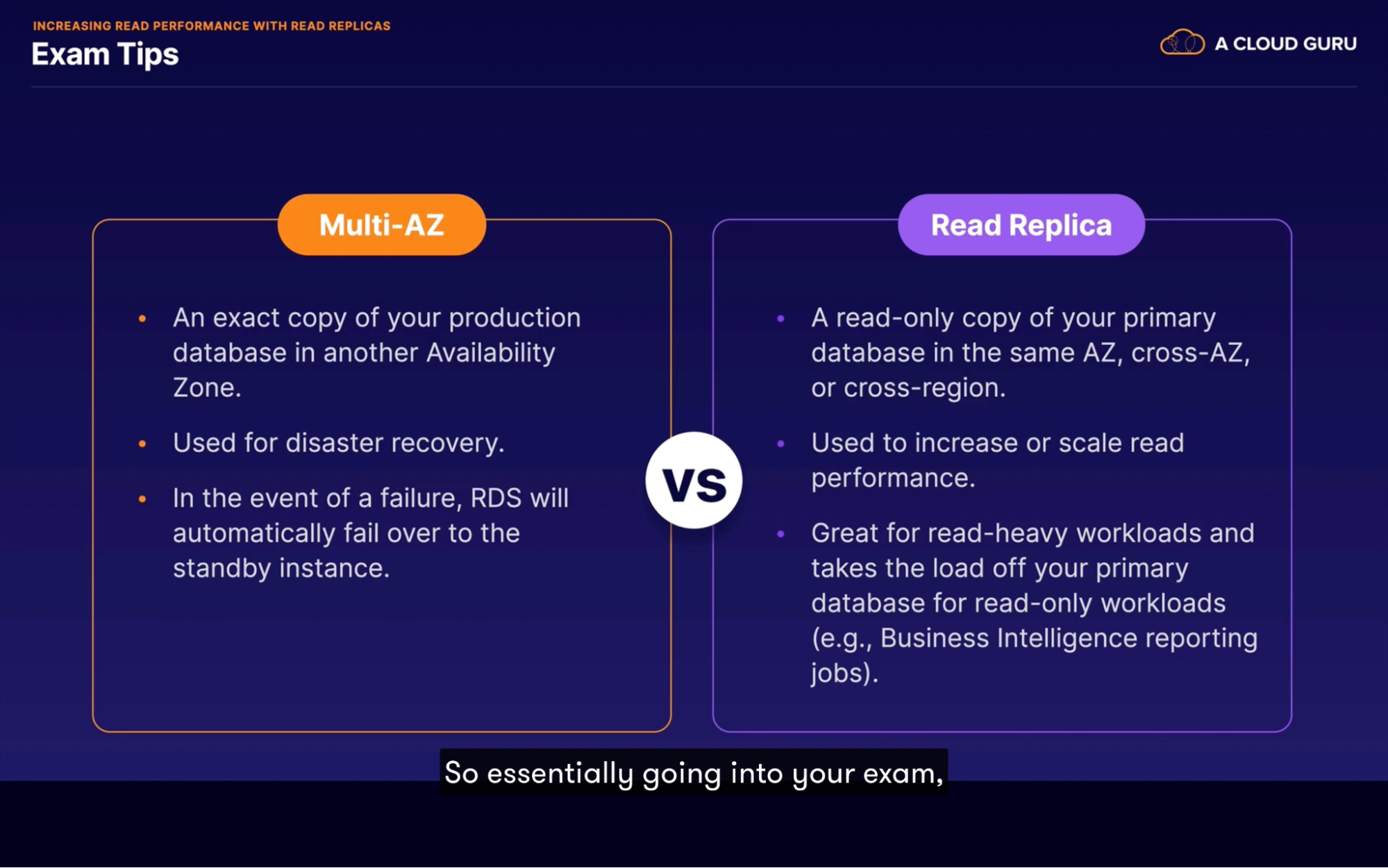
- Improve performance using read replicas
- Automated backups
- Improve RDS performance by read replicas
- How it works?
- You have exact replica of your primary database and you can use it for read querying
- Can be in cross AZ or cross region
- How tech works
- With read replica you get your own unique DNS endpoint. So 1 for primary and 1 for RR
- RR can promoted and make it independent database, and this will break the replication
- You do it when doing online processing where you can queuing to this database without affecting your primary
- Useful for
- Scaling read performance
- Requires automatic backups in order to deploy read replica
- Multiple read replica supported (5 per each DB instance)
RDS
When to use
- Used for online transaction processing workload- OLTP
OLTP
- Process the data from Transactions in real time
- Ex: when you order something from amazon it has to store order details in table
OLAP
- Process complex queries with large amount of data to analyze historic data
- ex: net profit for past 3 years
Download and Installation
Wget: download the software
Sudo yum installation: install the software
Database
- It’s a collection of data
- It’s organized data, and data is organized in a way that we can go and retrieve it
- If the data isn’t organized and can’t retrieve it, we need a database management system that makes it easier to work with data
- MongoDB
- Couchbase
- PostgreSQL
- MSSQL
- MySql
Type of database
- Flat files
- Regular file, could have text, comma separator, XML, YMAL
- Relational
- It’s a schema-based database
- Has rows and columns; spreadsheets
- Always have column numbers and data type of the entires
- Schemaless // NoSql
- Key-value pair (json)
Databases
MongoDB
Steps to installation:
- Installation MongoDb server
- Working in a server to create, read, update, and delete database
TODO
Create a database
- Use employees // will create employees database
Create a collection(table)
- Is a logical grouping of document(json pages). It’s like a table
- db.createCollection(“staff_info”) // create a collection/table
- db.staff_info.insert({name:”John”,phone:”1234567890”,status:”okay” }) // insert value to the table
- Calling a method on collection
- Insert an array of values
- Show collections // to see list of collections
- db.staff_info.find() // see all the entries, select all
- db.staff_info.find({name:”John”}) // gives entry named John
Update database
- Update a record in database
- db.staff_info.updateOne({name:”John”}, {$set:{status:”Not oKAY”}})
- Find the name John
- Update the status with that name from Okay to Not oKAY
Delete a record
- db.staff_info.remove({name: “John”}) // remove record named with John
- db.staff_info.drop() // drop the collection/table
- db.dropDatabase() // drop database
- Will delete data in the database
Bulk import data
- Create a database and import data from csv file
- mongoimport -d cityinfo -c cities --ype CSV --file ./cities.csv --headerline
Couchbase
- It’s N1QL(non-first normal form query language) // Nickel
- Stores document in JSON
- Looks like sql
Installation steps:
- Install couchbase server
- Start and setup(for login to the server) server
- Connect to a server
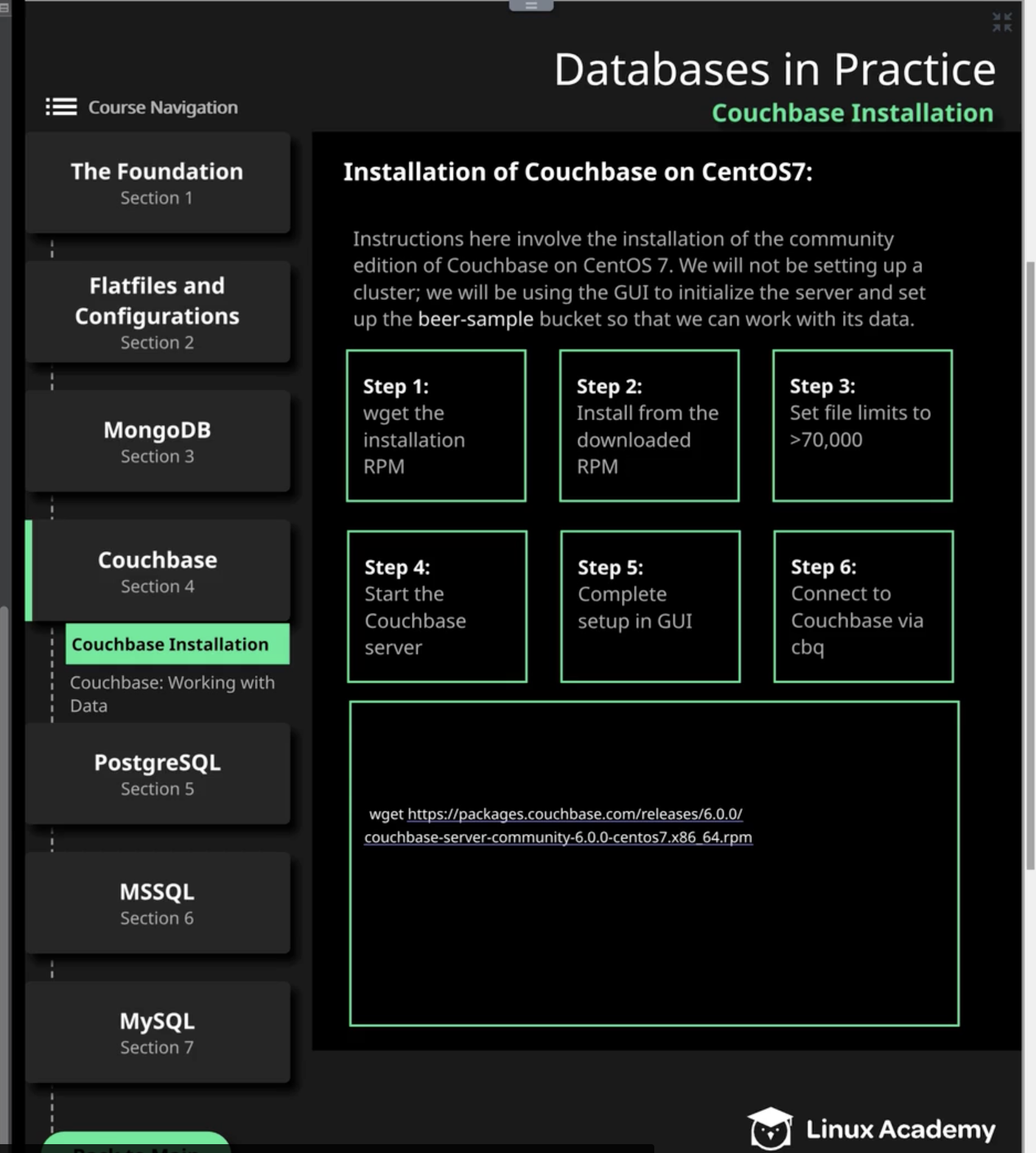
TODO

- create a bucket
- It holds a document // S3 bucket
- The document is object, descriptors for different items
- Create a document
- Query: document name/id & JSON Data
- Index a bucket to query data (query like SQL) // to read bucket
- To perform actions to look up things
- Update the value in bucket
- Clean up bucket
PostgreSQL
- RDBMS Database
- Is a Sql standard compliant and requires a schema
Installaton
- Install Postgre
- Intialize database server
- Enable and start the server/service
- Connect to PostgreSQL
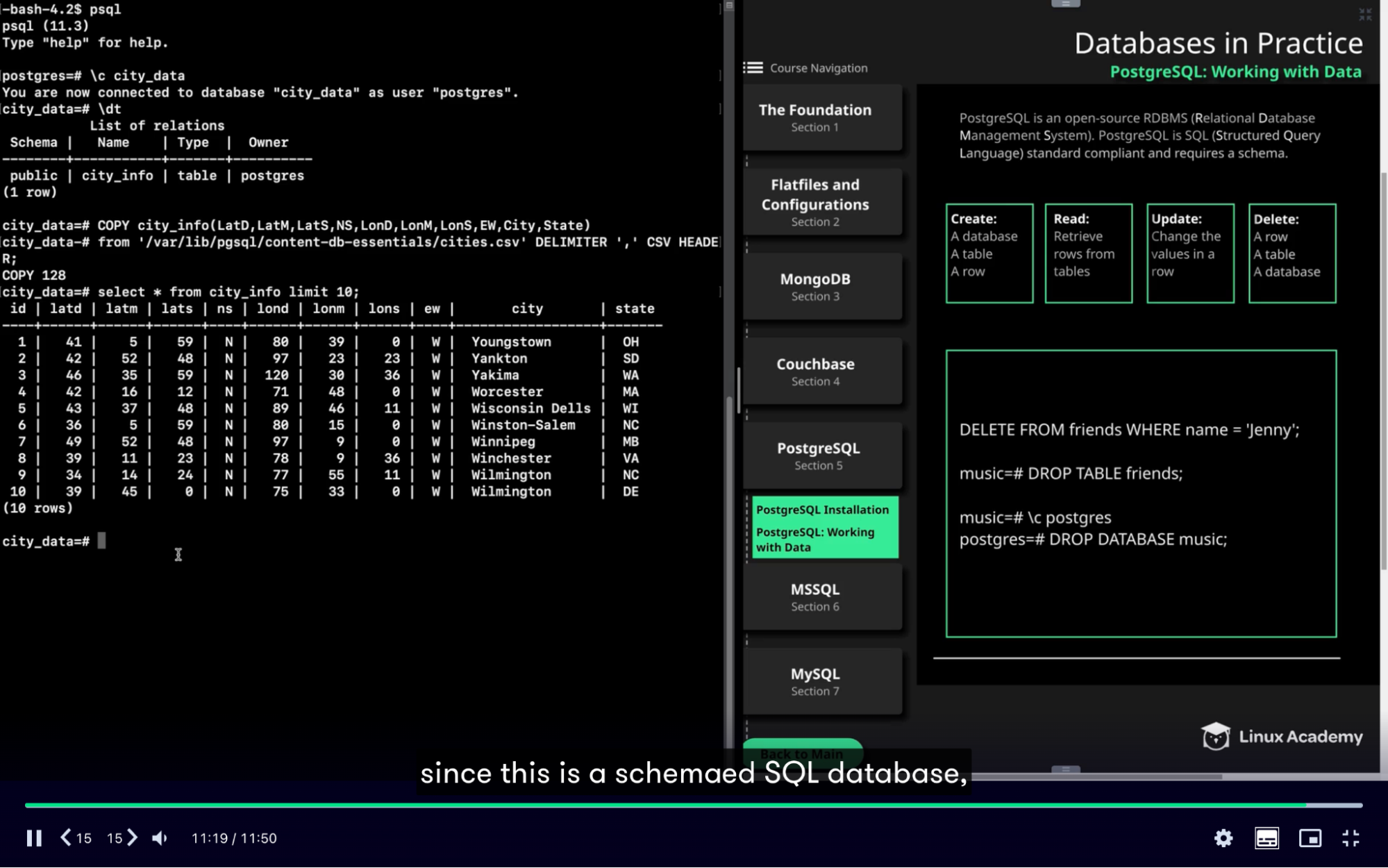
TODO
- Create database music; // to create music database
- Create table friends() // to create table with schema
- Insert into friends VALUES (‘John’, ‘123456’, ‘jessy’’) // insert values in the table
- Update friend set status=‘mine’ where name=’John’;
- Delete from friends where name=’John’; // to delete data
- Drop table friends; // to delete table
TASK
- Copy csv data into the table
Postgres vs MySql
Postgres: is an object-relational database management system
- Includes features like table inheritance and function overloading // Key difference in comparison with MySql
MySql:
Postgres | MySql |
RDMS | RDMS |
object-relational database management system - features like table inheritance and function overloading
| No features included such as table inheritance and function overloading |
Offers Advanced features that are difficult to set up but boost database for specific use cases | Requires less expertise to manage and boost higher performance |
Support for a programming language like .net, js, python |
|
Use case: more complex websites and apps that need highly customizable database solution | Use case: - web base application
- Used when Speed is a big concern
- With No additional features
|
| Lightweight and high-performance |
Support: open-source - Fewer resources compare to MySql
- You may have to troubleshoot a issue on your own when the problem is complex
| Support: open-source - More popular and that’s why it has more resources than any other tool
|